Series
A pond series is a schema-typed, ordered collection of events. Two flavours, same shape:
TimeSeries<S>— immutable, complete data. Built once, queried many times. Every transform returns a newTimeSeries.LiveSeries<S>— mutable, append-optimized buffer. Same schema type asTimeSeries, same operator surface (filter, rolling, aggregate, ...), with subscriber semantics for streaming use.
Both carry the same S schema type. A transform that works on
TimeSeries<S> works on LiveSeries<S>, and the type system
threads the schema through both paths identically. Choose by data
shape, not by which operators you need.
Events
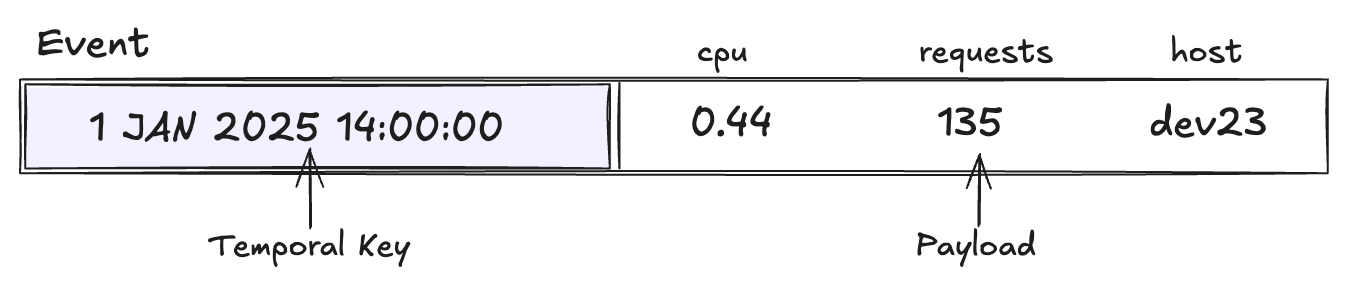
The building block. An Event<K, D> is a temporal key plus a typed
data payload.
import { Event, Time } from 'pond-ts';
const e = new Event(new Time(1735689600000), {
cpu: 0.42,
host: 'api-1',
});
e.key(); // Time | TimeRange | Interval — see Temporal keys
e.begin(); // number — earliest instant in the key's extent
e.end(); // number — latest instant
e.get('cpu'); // 0.42 — typed via the schema
e.data(); // { cpu, host } — full payload
Events are immutable. event.set('cpu', 0.5) returns a new event;
the original is unchanged.
You rarely construct events directly — new TimeSeries({ rows })
and live.push([...row]) build them from row tuples that match the
schema. Direct construction is mostly for tests and advanced
embedding.
See Temporal keys for the three key shapes.
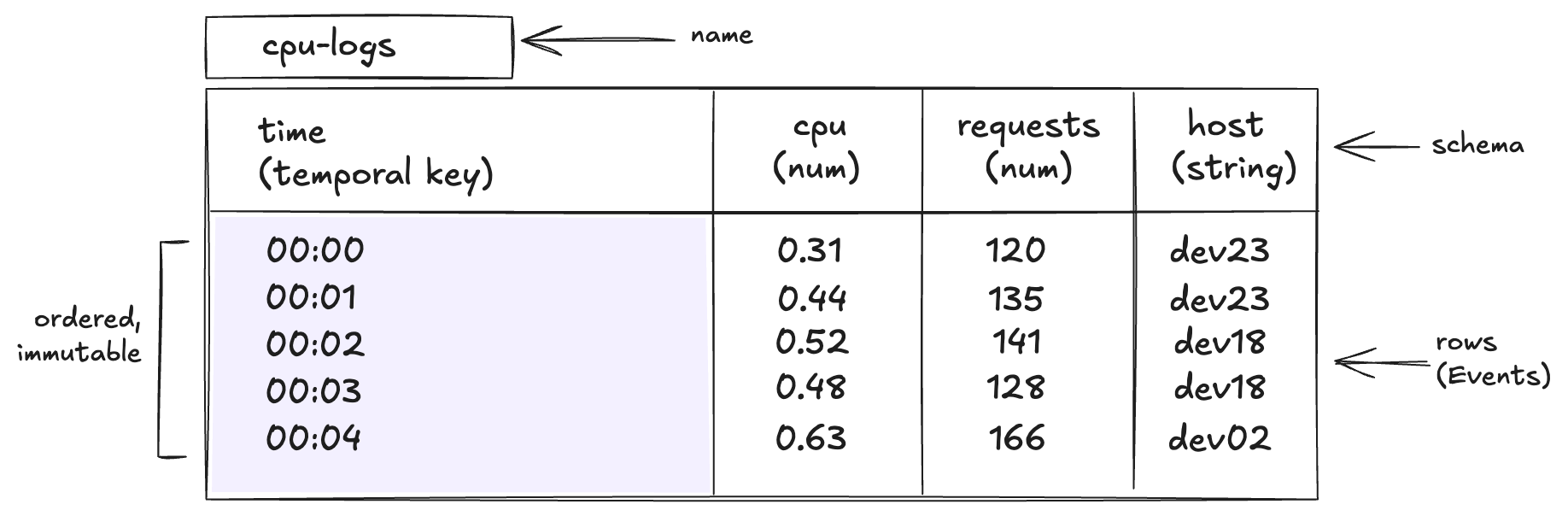
TimeSeries<S> — batch
An ordered, immutable, schema-typed collection of events. Built from a row array or via JSON; queried, transformed, and reduced through method chains.
import { TimeSeries } from 'pond-ts';
const cpu = new TimeSeries({
name: 'cpu',
schema,
rows: [
[0, 0.42, 'api-1'],
[1000, 0.51, 'api-1'],
[2000, 0.38, 'api-2'],
],
});
cpu.length; // 3
cpu.first()?.get('cpu'); // 0.42
cpu.tail('1m'); // new TimeSeries with the trailing 1m of events
cpu.aggregate(seq, m); // new TimeSeries, bucketed
Every transform returns a new TimeSeries — no in-place mutation.
This is what makes pond's compositional method chains safe and
predictable: the operator's input is unchanged, and intermediate
results can be held as their own values without worrying about
later operators perturbing them.
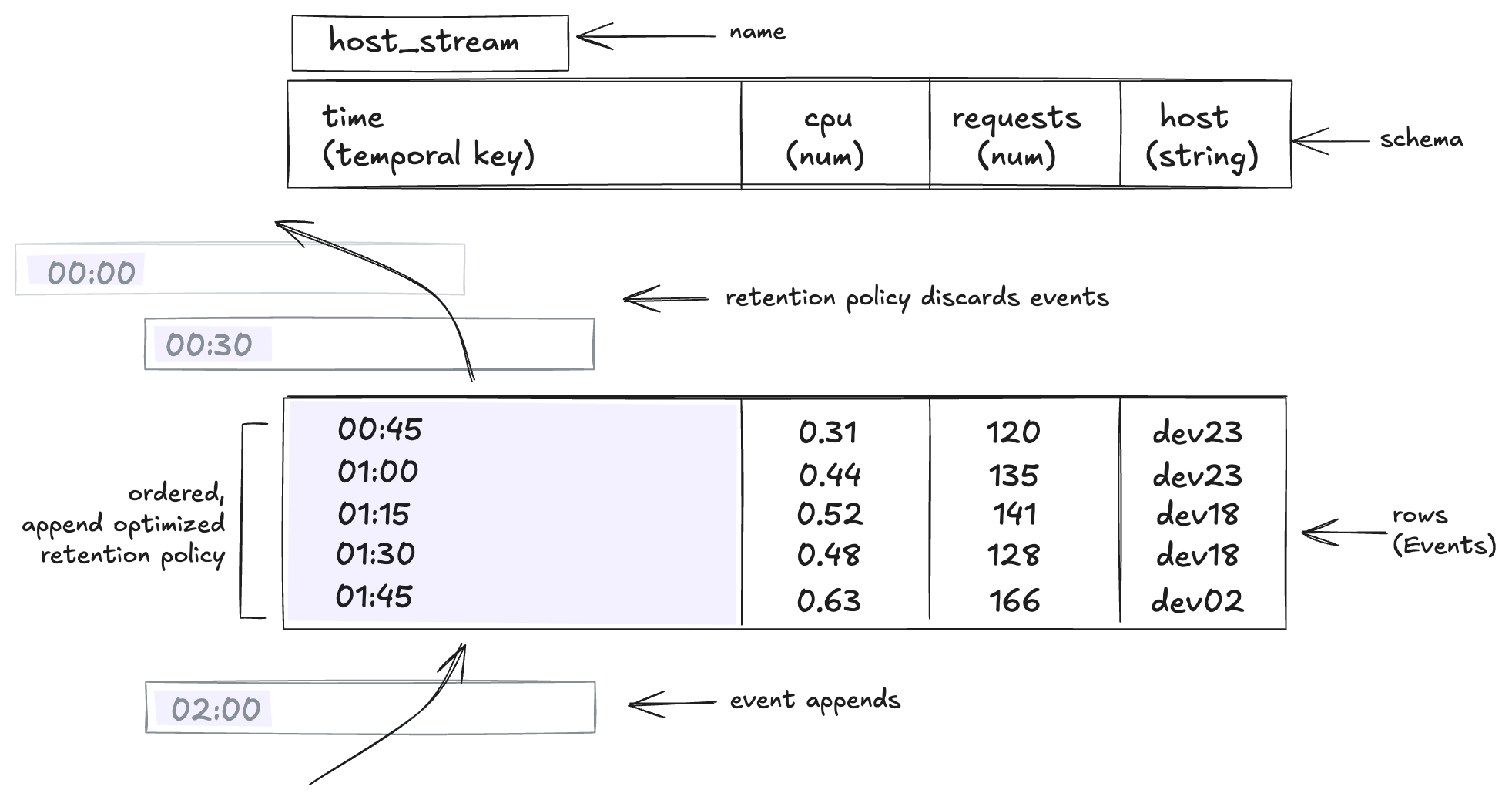
LiveSeries<S> — streaming
A bounded, append-optimized buffer with the same schema as
TimeSeries. Designed for streaming ingest: data arrives over time,
the buffer holds a configurable retention window, subscribers react
to new events.
import { LiveSeries } from 'pond-ts';
const live = new LiveSeries({
name: 'cpu',
schema,
retention: { maxEvents: 10_000 },
});
live.push([Date.now(), 0.42, 'api-1']);
live.length; // 1
live.last()?.get('cpu'); // 0.42
live.on('event', e => console.log('arrived:', e.get('cpu')));
The same operator surface is available — live.rolling('1m', ...),
live.aggregate(seq, ...), live.partitionBy('host').rolling(...),
live.filter(...), etc. — but operators on a live source return
accumulator types (LiveRollingAggregation, LiveAggregation,
LiveView) that maintain incremental state and emit events as the
source advances.
live.toTimeSeries() snapshots to an immutable batch series at any
time — the snapshot is independent of future pushes.
Batch and streaming as peers
The two-flavour design is deliberate:
- Same schema type. A
LiveSeries<S>can be snapshotted to aTimeSeries<S>and back; both shareSexactly. - Same operator surface.
aggregate,rolling,reduce,partitionBy,filter,map,selectall exist on both. Method names match, parameter shapes match. - Different cost models. Batch operators walk a known dataset once. Live operators maintain incremental state and pay per-event costs as data arrives.
- Different output types. Batch returns new
TimeSeries<S>; live returns subscriber-shaped accumulators that satisfyLiveSource<S>.
Pond is not a full streaming engine like Apache Beam or Flink — no watermarks, no exactly-once delivery, no retraction handling. Live ingest accepts ordered events with a bounded grace window for moderate reordering. See Late data for the trade-offs.
Composition rules
| Source | Operator returns | Mutation model |
|---|---|---|
TimeSeries<S> | New TimeSeries<S'> | Source unchanged; chain freely |
LiveSeries<S> | LiveView<S'> or accumulator type | Source unchanged; subscribers attach |
| Accumulator | New LiveView / accumulator | Same — accumulator-of-accumulator |
Both sides are append-only-from-the-source's-perspective. A
TimeSeries is fully complete when constructed; a LiveSeries
grows as push is called and shrinks only via retention. Operators
attached to a live source see new events arrive but never see old
events change.
Where this shows up
- Schema and construction details —
TimeSeries({ rows }),LiveSeries({ schema, retention }), JSON round-tripping — see Creating series. - Querying and slicing —
at,first,last,tail,between— see Queries and Temporal relations. - Windowing operators —
aggregate,rolling,reduce— see Windowing. - Streaming-specific concerns — ordering modes, grace, the data-as-clock model — see Late data.
- Partitioned series — split a series by column value into per-key sub-series — see Partitioning.